产品设计过程中,各方都会提出对应的需求,那么产品经理又该如何抉择,对需求优先级进行排序呢?笔者认为使用KANO模型会是不错的办法。
在项目中,设计需求从四面八方而来,你也许经历过下面的某个场景:
1. 竞品调研
PM:竞品出了XX新功能,我们也不能落后,紧锣密鼓跟上。
2. 用户反馈
User打客服热线,咨询退货要如何申请。
客服将需求反馈给PM,目前用户只能通过客服进行人工登记申请退换货,可考虑在App上加上售后管理模块。
3. 业务需求
法务:我们XX条款一定要强制让用户看到。
4. 产品体验
某次走查中,发现闪屏页在各款机型适配显示上有问题,在某机型上变形挤压了。
… …
通过各种渠道反馈的需求收集,需求池越来越满,有些需求,可以主观判定是否排定开发,比如上面所举例的售后模块、闪屏适配问题(保证用户体验,不然用户会流失)、条款强弹(App上线过审时,某些条款的出现时审核的条件之一)。
而类似场景1的需求,要科学理性地评判。下面一起了解下KANO模型,它可以在我们客观评判上助一臂之力。
一、KANO模型是什么
KANO模型是由东京理工大学教授狩野纪昭(Noriaki Kano)建立的,用于对需求用进行分类和分级排序。
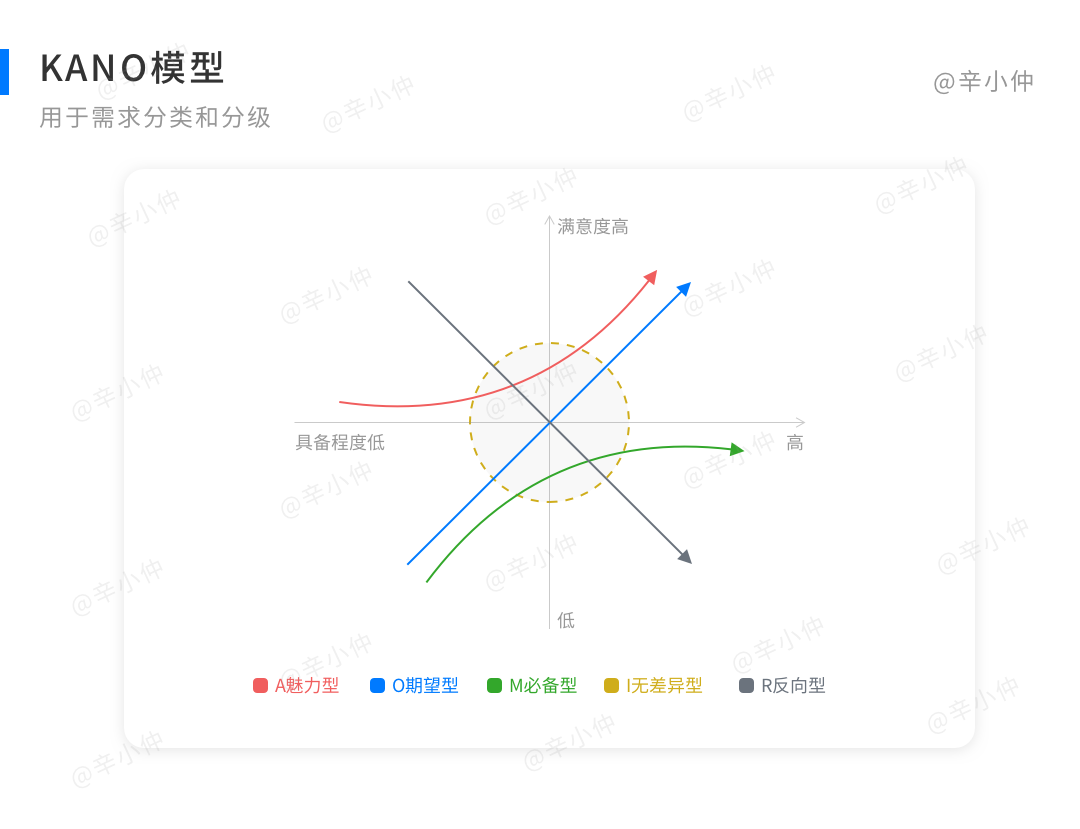

KANO模型将需求划分为必备型需求、期望型需求、魅力型需求、无差异需求、反向型需求。
它描述了需求具备程度和用户满意度之间的关系。

- 必备型(Must-beQuality)需求:呈正相关
- 期望型(One-dimensional Quality)需求:呈正相关
- 魅力型(Attractive Quality)需求:呈正相关
- 无差异型(Indifferent Quality)需求:无相关
- 反向型(Reverse Quality)需求:呈负相关
正相关表示具备程度越高,用户满意度越高;负相关表示具备程度越高,用户满意度越低;无相关表示两者间无特定关系。
下面通过案例来了解下:
1. M必备型需求
必备型:用户觉得理所应当的功能,未实现用户会不爽,实现了用户觉得应该。
在产品生命周期建设阶段,必备型需求是主流需求,项目团队实现的重点,它关系着产品的正常使用。
比如:有道云笔记可以批量选择笔记进行移动、复制、删除等操作。
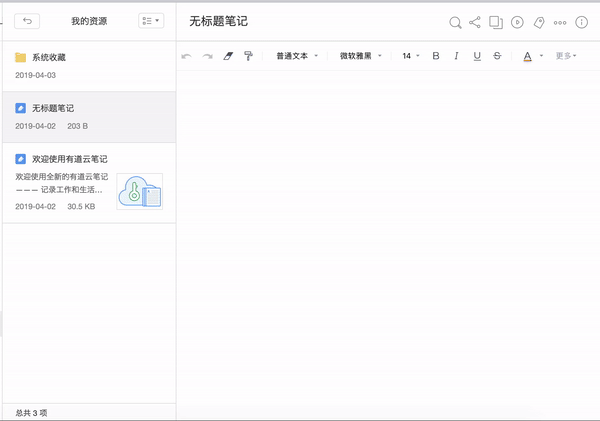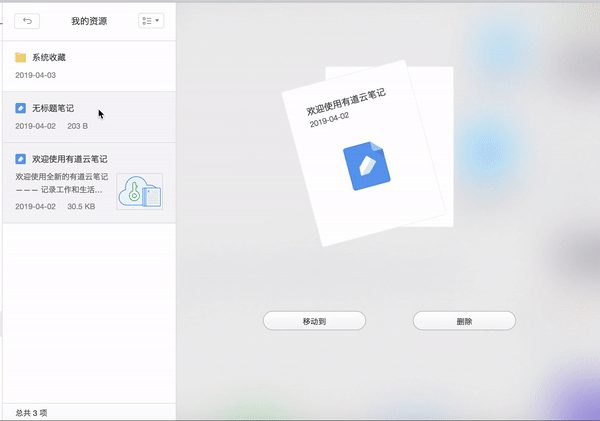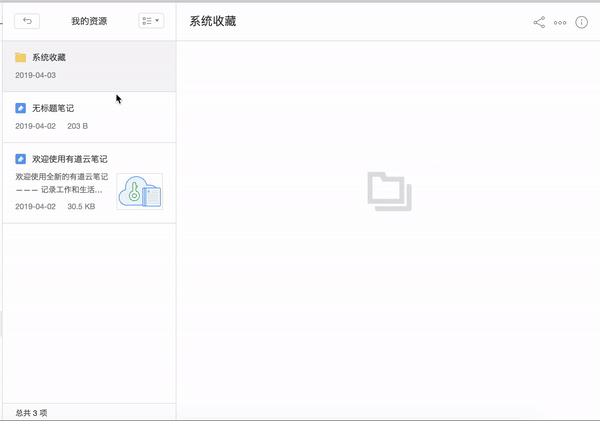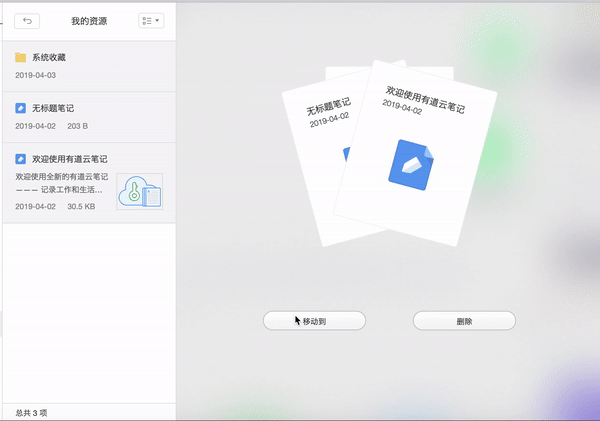
2. O期望型需求
期望型:用户带有期待的功能,未实现用户会失落,实现了用户会满意。
在产品生命周期成长阶段,基本功能基本落实,必备型需求库存减少,慢慢会有更多期望型的需求加入,开始用户体验建设。
比如:火狐浏览器在浏览器异常关闭重启后提供了2种选择,一种恢复浏览,另一种就是开启新的浏览。此处的恢复浏览功能就是用户的“期望型需求”。
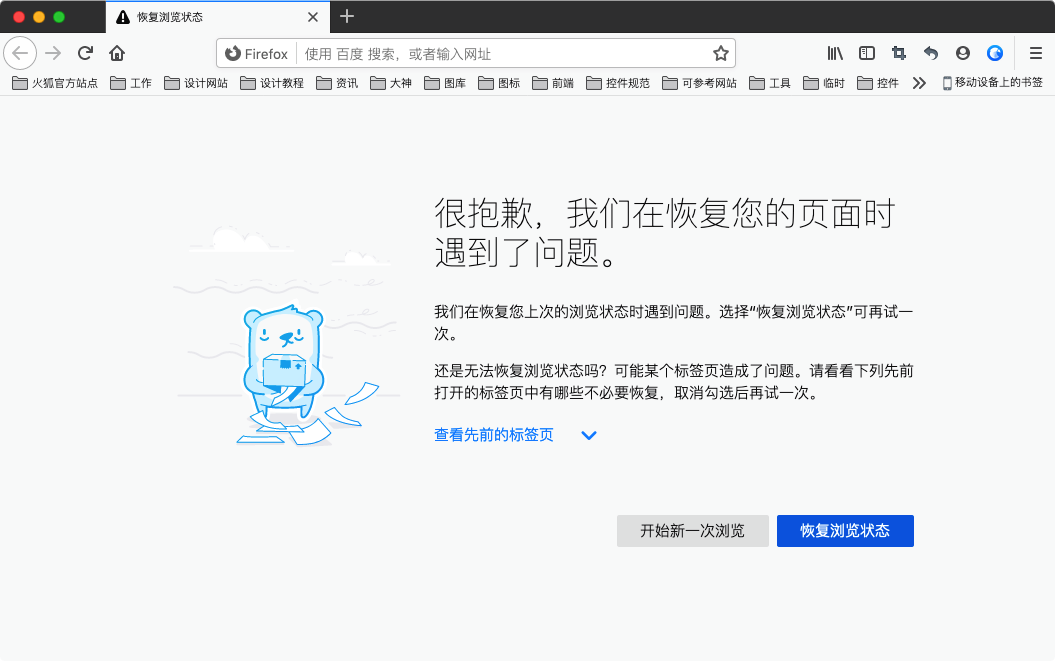
3. A魅力型需求
魅力型:用户意想不到的功能,未实现用户无感(哈哈哈因为根本想不到还有这个操作),实现了用户会大吃一惊拍案叫绝。
魅力型功能可以是一个产品的核心竞争力,它能够快速拉开和竞品距离,让产品独具一格,这类需求百里挑一。
比如:在美团点餐提交订单没有点主食,会提示用户是不是忘记点主食了,点击按钮在本窗口弹出主食让用户添加。若不提供此需求,用户满意度不会降低;若提供此需求,用户满意度会有很大的提升。
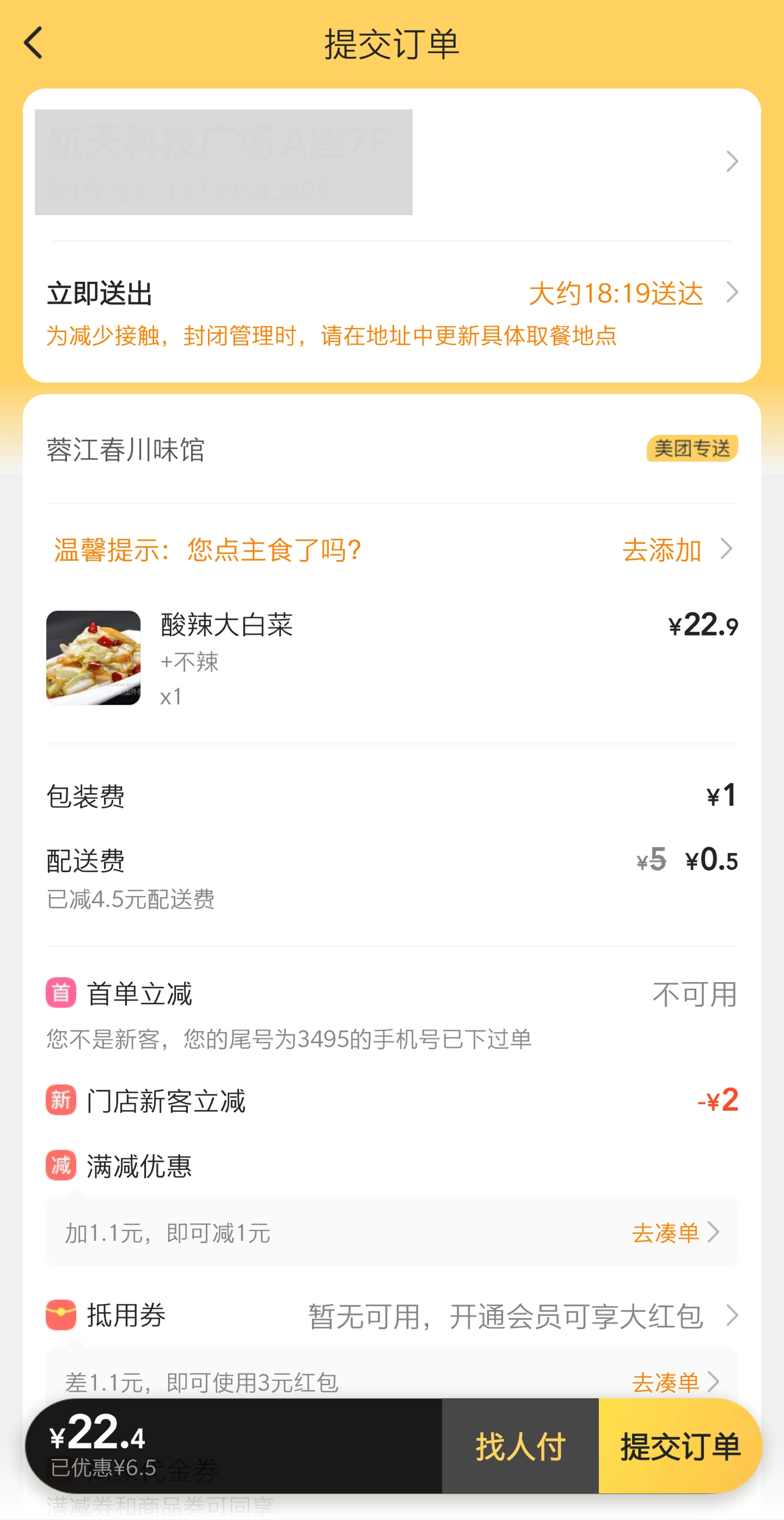
当然,我们不能说美团因为这一个功能使其领先于竞品,在体验美团App外卖过程中,还有很多其他细节地方同样能够体现类似的“温馨提示”。
比如说:
- 「点外卖时」,你在浏览商家列表,若长时间没有跳转,会在顶部“发现好菜”旁边出现提示“纠结吃点啥点这里”的提示,引导用户浏览“发现好菜”列表找到想吃的东西
- 「提交订单后」,用户可以填写备注内容,快捷标签能够让用户不用填写直接点击标签提交即可
- 「在支付环节」,以返利方式刺激用户绑卡支付
- 「订单完成后」,点击取消订单按钮,会有对话框进行二次确认。在二次确认对话框中提供一个文字链入口,方便用户重新修改信息。一方面可以减少无效订单的冗余数据,另一方面也方便了用户(若无快捷入口,用户需要取消订单后重新下单)
- … …
这些带有“期待型”和“魅力型”特质的小功能,贯穿了“用户点外卖场景”的整个「体验地图」,从而让整个App在无形中更好用,也许在“有用性”上美团App和其他竞品没有同质性的区别,但“好用性”的特质让美团App和其他产品形成了区分。
这种区别有点说不清道不明,因为我们日常在体验App中,好的体验往往是行云流水不经意间的。不知道你有没有类似的感觉?
很难有产品像今日头条仅凭一个“用户差异化智能推送”就树立产品差异性的,如果不能一招制敌,那就从细节出发,逐步积累实现的魅力型和期望型功能让用户有更好的体验也是不错的制胜法宝。
4. I 无差异型需求
无差异型:用户觉得可有可无的功能,实不实现都无所谓。
无差异型需求的实现不能给产品锦上添花,那为何要浪费资源实现呢?
比如:好好住APP的重力感力应用,如果你在好好住App中获得过徽章,进到「我的」页面你会不经意间发现一个小惊喜,如录屏所示,徽章会跟着手机的晃动而晃动,从空中掉入地面,有地心引力般。但该功能显得有点鸡肋。
5. R反向型需求
反向型:用户觉得不如不加系列功能,加上反而累赘,可能会给用户带来厌恶感。
一个产品若是有诸多反向型需求,就像是一粒老鼠屎坏了一碗粥,再好的产品都有了污点。无差异型需求和反向型需求是要杜绝的。
暂时找不到案例,你想到了可以留言一起交流哦~
6. 各类求之间的关系
需求的定性并非一成不变,随着互联网技术的发展、用户获得越来越好的体验、交互方式的日益成熟,未来“魅力型需求”可能成为“期望型需求”,“期望型需求”成为“必备型需求”。
比如:在2G时代,聊天发送视频和图片是“期望型需求”,到3G、4G时代,则演变成了“基本型需求”。
技术在革新,我们日常使用的产品或体验的服务都在越来越好~
二、问卷调查结合KANO模型进行需求分类
你在上述需求案例中,可能心中有不同的答案——
- XX需求我不觉得是「魅力型」,我觉得应该是「期待型」
- XX需求为什么是「必备型」?它不实现也不影响我使用啊,应该是「无差异型」吧
- 你上面举的好好住的重力感应应用案例,我就觉得挺好的,应该是「必备型」吧
- … …
作为用户,这是你的看法,其他用户有其他看法,将这些声音收集起来,整理数据进行定量分析,得出最终的结论,通过数据来看结果。
我们可以通过问卷调查的形式,具体流程如下——
1. 设计问卷
将需求池的需求导出,罗列出清单,每个功能点对应清单中的一项,而每一项需要设计2道问题,2道问题为正反提问。
例如:「浏览器意外关闭后是否可以恢复上次浏览」的需求,设计的问题为——
问题1-1、若浏览器崩溃后重启可以恢复上次浏览,你的感受是?
A、非常喜欢 B、理应如此 C、无所谓 D、勉强接受 E、很不喜欢
问题1-2、若浏览器崩溃后重启不可以恢复上次浏览,你的感受是?
A、非常喜欢 B、理应如此 C、无所谓 D、勉强接受 E、很不喜欢

通过以上格式,问卷的「问答」部分已经完善,问卷前文加上调研目的、选项说明和感谢的话,就可以开始实施调研了。
关于选项说明,因为每个人对选项的理解及解读有所不同,因此有必要加上此部分的说明,尽可能确保调研对象对各个选项有共同的认知,避免错误解读。
诸如可以在问卷中添加以下说明——
- 非常喜欢:有强烈的认同感
- 理应如此:事实上应该存在的
- 无所谓:没有太大的诉求,可有可无
- 勉强接受:对此没有太大的感觉,但也可以接受
- 很不喜欢:排斥甚至厌恶
2. 开展调查
开展问卷调查前,先招募一定的目标用户,然后进行问卷发放和回收,问卷发放可通过纸质也可通过电子的形式,招募数和发放形式根据你所拥有的资源而定。若资源和时间有限,C端的目标群,在公司内部进行随机抽取也是一个不错的选择。
当然,问卷中存在废卷的情况,因此招募的数量不能太少。
3. 整理数据
回收问卷后开始对数据进行整理,将无效问卷剔除,无效问卷不除外以下情况:
- 所有问题的答案都一致
- 大量题目未作答
剩下的就是有效问卷,有效问卷中的每个功能点参照以下表格进行对照。

- A(魅力型):对应提供此功能「非常喜欢」、不提供此功能「理应如此、无所谓、勉强接受」
- O(期望型):对应提供此功能「非常喜欢」、不提供此功能「很不喜欢」
- M(必备型):对应提供此功能「理应如此、无所谓、勉强接受」,不提供此功能「很不喜欢」
- I(无差异型):对应提供此功能「理应如此、无所谓、勉强接受」,不提供此功能「理应如此、无所谓、勉强接受」
- R(反向型):对应提供此功能「非常喜欢、理应如此、无所谓、勉强接受」、不提供此功能「非常喜欢、理应如此、无所谓、勉强接受」
- Q(可疑结果):对应提供此功能「非常喜欢」、不提供此功能「非常喜欢」或对应提供此功能「很不喜欢」、不提供此功能「很不喜欢」。
因为此结果不可能发生,不然就自相矛盾,所以定为可疑结果。比如你不可能非常喜欢「浏览器崩溃重启后可以恢复上次浏览」,又非常不喜欢。
参照对照表,每份问卷的每个功能点都有了分类结果。
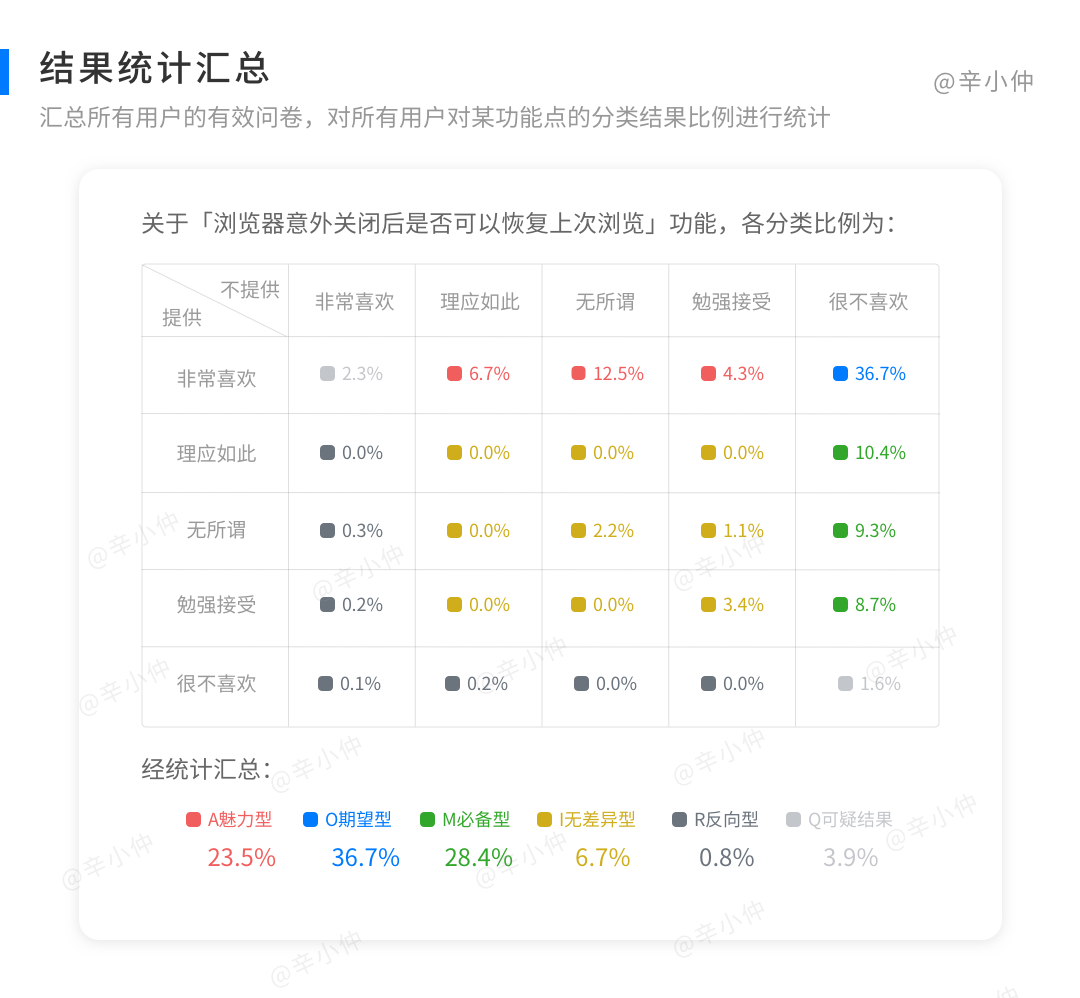
例如:某问卷中针对「浏览器崩溃重启后可以恢复上次浏览」功能,编号001用户所持的态度如下所示,参照对照表,对应的分类为M(必备型);同理,编号002用户所持的态度对应的分类为O(期望型)。

4. 结果分类
接着汇总所有用户的有效问卷,对所有用户对某功能点的分类结果比例进行统计,分别得出A(魅力型)、O(期望型)、M(必备型)、I(无差异型)、R(反向型)、Q(可疑结果)所占的比例,比例值最大对应的类别就是对应功能点的分类类别了。
如上案例:针对需求「浏览器崩溃重启后可以恢复上次浏览」,每份问卷的选择结果都不同,经统计汇总,“A(魅力型)、O(期望型)、M(必备型)、I(无差异型)、R(反向型)、Q(可疑结果)”所占的比例分别是“23.5%、36.7%、28.4%、0.8%、6.7%、3.9%”。其中O的比例最高,占36.7%,所以该需求为O(期望型)。
三、对多个需求进行排序分级
通过上述步骤,我们可以对所有功能点的分类结果进行定论。
如果为了更加直观看到分级结果以及对同类需求的优先级进行排序,可以对数据再进一步计算,确定Better-Worse系数,结合四象限绘制散点图。
总的排序规则为——
剔除“无差异型和反向型需求”,不同类别需求的优先级排序规则是“必备型 > 期望型 > 魅力型”,同类需求的优先级排序规则是“Better值越高,优先级越高”。
当然规则是死的,每个产品的特质是不同的,整个优先级的排序规则可以结合公司资源、需求方的压力、开发资源进行微调。
1. 确定Better-Worse系数
我们知道,某个点确定了X和Y坐标值,就能在四象限中定位一个点。
这里,每个需求点的Y坐标和X标分别对应Better系数和 |Worse系数|(|Worse系数|指Worse值的绝对值)。
Better系数,结果为正,表示用户对某功能或服务实现的满意程度,该值越接近于1,表示实现某功能或服务后,满意程度越强;
Worse系数,结果为负,表示用户对某功能或服务不实现的不满意程度,该值越接近-1,表示不实现某功能或服务后,不满意程度越强。
计算公式分别是:
Better/SI =(A+O)/(A+O+M+I)
Worse/DSI = -1 *(O+M)/(A+O+M+I)
2. 落入四象限图
各个需求的Better-Worse值统计完成后,便可以落入四象限图了。
例如:代入公式计算,将6个功能点的Better-Worse系数计算得出,落在四象限的图如下所示:
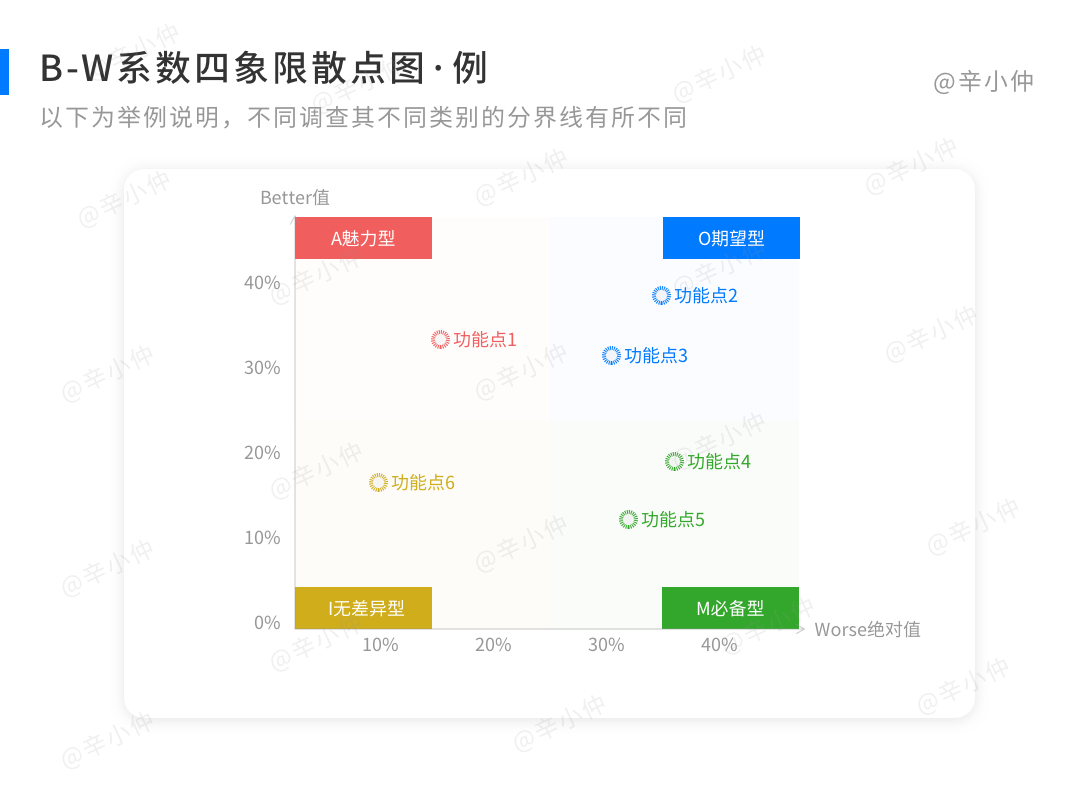
根据排序规则,优先级为“功能4>功能5>功能2>功能3>功能1”。
四、总结
众多需求琢磨不定,在时间充裕的前提下,不妨通过问卷的形式在目标用户群进行调研,通过KANO模型,我们可以对需求进行:
- 分类,通过分类的结果指导实现方向,剔除“无差异需求、反向型需求”,保证“必备型需求、期望型需求”,挖掘“魅力型需求”
- 分级,明确不同类别和相同类别需求的优先级
切勿一股脑毫无根据全凭主观意志拍板,XXX需求就这么定了,就这么排,就这么做。
作者:辛小仲;一名正在成长的交互设计师,公众号:辛小仲。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


