让技术同学“看得懂、埋的对、实施快”


GrowingIO 高级技术顾问,毕业于北京大学,Extron 认证工程师。服务过奇瑞汽车、中铁建工、滴滴等头部企业,有丰富的技术部署经验。
假设一个场景:我们想要采集一个广告投放页的数据。
首先,我们与技术同学描述用户进入 App 开屏页所面临的场景:浏览—点击—跳转到广告页;接着,我们提出埋点需求。
点击数据分为有效点击和无效点击两类,但是由于技术侧同学并不会纠结此问题。他便随便从网上下载了一个闪屏页框架,集成到项目中。
在该框架下,点击动作被拆解为:按下,抬起。而我们平时认为的点击动作应该是:短时间内按下和抬起两个动作同时出发。
由于框架的目标是增加点击率,即让看到广告详情页的人变多。所以,当用户按下的时候,就已经触发了跳转到详情页的操作。
大部分非目标客户都会很急躁的退出广告详情页,而真正看到广告并感兴趣的人员则会主动进入广告详情页。
由此带来的洞察结果是:点击率高,转化效果差。市场侧的同学误认为是广告设计的失败,这会影响下次广告投放的视觉效果或投放策略。
通过上述例子,我们得出结论:数据采集的时机和技术侧的实现方式会大大影响业务侧的决策。
“九层之台,起于累土。”在形成一套可被洞察的数据之前,数据采集是最基础也是最关键的步骤。只有数据采得准,这个洞察结果才能在你做商业决策时提供帮助。否则将适得其反,再漂亮的数据分析也带不来实际的效果。
但是在埋点方案的实际实施过程中,我们可能会遇到以下困惑:
- 如何和技术端沟通你的埋点需求?
- 技术同学是否很快理解并落地?
- 最终数据生产结果是否符合你的预期?
- 前期沟通业务不明确。例如程序员不清楚有效点击和无效点击的区别,只是单纯地从技术层面完成埋点;
- 采集时机口径对不齐。你希望采集数据的那个时机,技术同学并不明确;
- 采集点没有统一管理。如果没有统一的渠道去管理点击、浏览等数据,你的埋点方案将因繁琐的程序而无法落地;
- 版本更新。比如你在新旧版本之间进行比对时,无法发现数据的变化。
数据采集关乎数据质量,它需要产品及业务侧同事做出让技术同学“看得懂、埋的对、实施快”的技术落地方案。
什么是无埋点?我们先来看看你是否遇到过以下这些场景:
- 做了一场运营活动,需要在用户的每一次点击行为上都埋点,却缺乏产研资源;
- 想衡量交互细节以推测用户行为之间的关联,却苦恼于繁琐的工序;
- 想查看用户在访问时的一切行为轨迹,探索用户使用产品场景;
- 想要快速地对比新旧版本,衡量发版效果;
- 想要分析的事件,没有事先埋点;
- 新功能上线时,发现有一个重要的元素没有埋点。
针对以上问题,无埋点都可以很好的解决。其实无埋点就是人物、时间、地点、内容、方式的数据采集方式,通过 GrowingIO 的圈选(可视化定义工具)功能,我们可以所见即所得地定义指标。
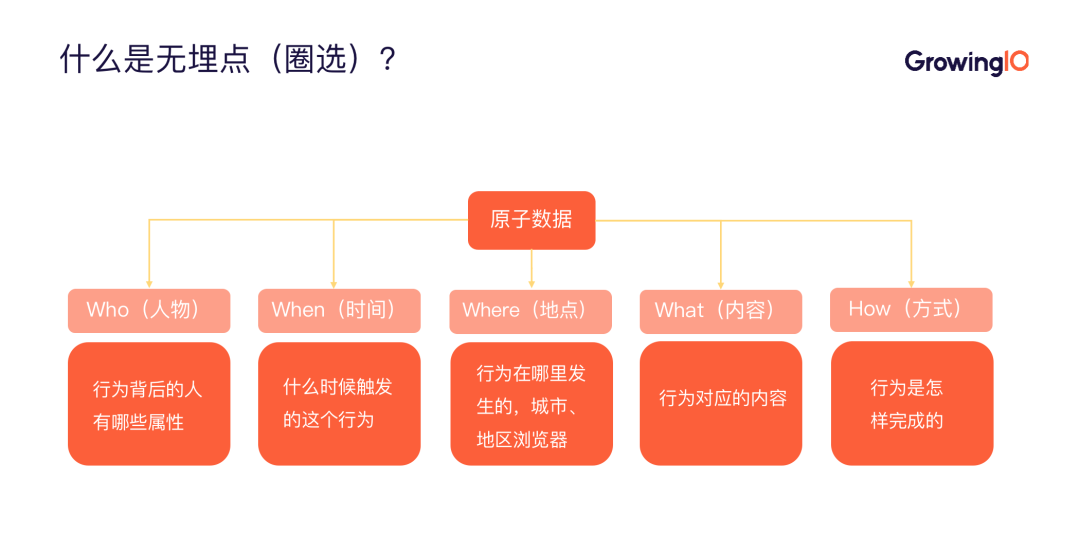
- 人物:人的属性,包括 ID、性别、所在区域等;
- 时间:触发行为的时间;
- 地点:行为发生的城市、地区浏览器等;
- 内容:行为的对象,如按钮等;
- 行为:行为的操作方式,如浏览、点击、输入等。
无埋点能够定义常见事件类型,尽可能地减少代码的使用,减少开发工作量。通过 GrowingIO 的圈选功能,我们能快速采集数据、定义指标、查看实时数据。
2.埋点和无埋点如何选择?
新的无埋点虽然简单便捷,但也有它自身的局限性。同时,我们离不开业务数据维度,所以传统埋点也不能放弃。
埋点和无埋点各有优势,面对不同的场景,我们需要明确目的、结合具体情况综合判断,选择数据采集的最优方式。
(1)埋点
- 优势
- 数据定义清晰,稳定性高,用户一旦触发事件,数据就能上报;
- 可以多次添加业务属性,以支持维度拆解和下钻分析。
- 劣势
- 需要提前规划,和开发团队沟通业务需求,跨团队协作确定埋点方案;
- 历史数据无法回溯,在下一个版本中才能看到。
- 适用于「监控与分析式」数据场景:
- 核心 KPI 数据
- 需要长期监控和存储
- 业务属性丰富
(2)无埋点
- 优势
- 自主性高,可实时查看数据,便于灵活采集;
- 无需等到发版便可回溯过去 7 天数据。
- 劣势
- 受制于产品开发框架和开发规范,任何一个路径发生改变都会产生影响;
- 维度预定义,无法拆分事件级维度,且无法采集滑动等行为。
- 适用于「探索式」数据场景:
- 交互属性强
- 突发问题快速及时分析
- 作为补充数据相互印证
综合以上,我们整理出了以下表格,方便大家更好的理解和选择:

当我们选择无埋点还是埋点时,只需要关注:该行为非核心指标且存在预定义无埋点指标中。
如果存在该预定义指标(即无埋点),且预定义维度也满足需求,那么,我们就要针对该无埋点的指标和维度进行观察,可放心选择无埋点。如果不存在或预定义维度无法满足观察该指标的角度,则需要通过埋点指标进行上报。
这最终会导致我们空有体系,无数可看。
如果将一整套的数据采集方案直接给到研发侧,业务场景描述和逻辑理解的差异会造成大量的沟通成本,最终导致低迷的实施效率。
所以,我们需要将条理化的指标体系梳理成实施需求。而解决该问题的关键点在于以下 4 个步骤:
1.确认事件与变量
- 事件:这是我们最终要分析的数据来源.,是一个结果性指标,比如支付成功;
- 变量:事件的维度或属性,比如用户性别、商品的种类;

- 需要思考:什么时间才是记录事件的合理时机。例如“分享成功” 事件面临 2 个时机:用户点击“微信”发生分享动作;用户分享后跳转到相应页面。不同的时机会带来不同的“分享成功率”。
- 所有数据使用者需要明确这一时机。

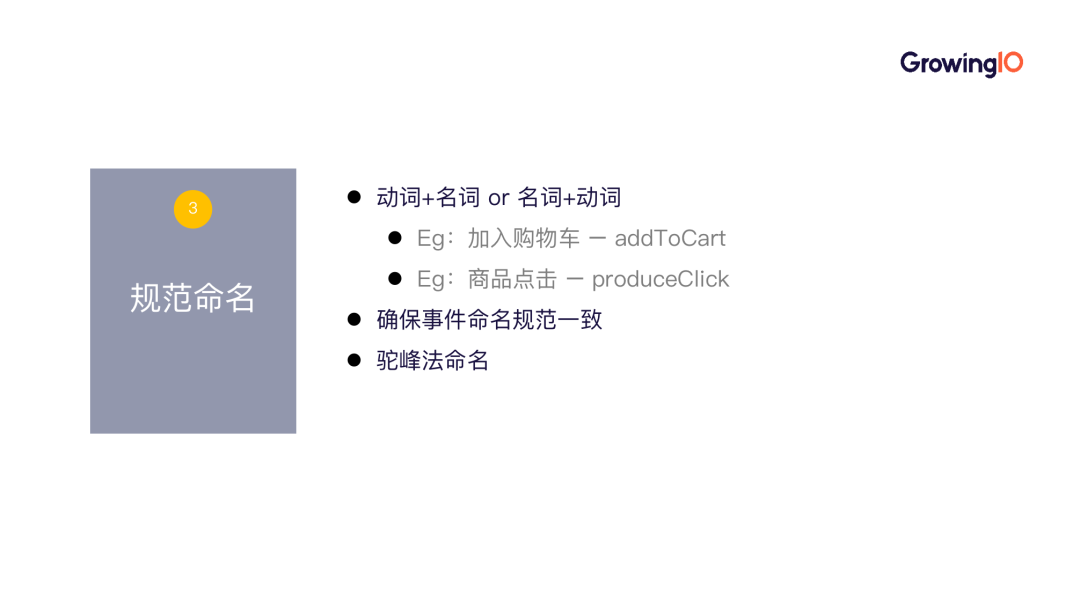
举个例子:某客户给双十一活动命名时采用拼音与英文结合的方式,这会使得程序员产生混淆,错误埋点。而规范的命名有利于程序员理解业务需求,高效落地埋点方案。
- 动词+名词 or 名词+动词:如加入购物车、商品点击。
- 使用驼峰法,即首字母小写,随后每一个关键单词的首字母大写:如 addToCart。
- 确保事件命名规范一致。
- 业务部门必须基于业务指标,明确实施埋点的优先级。因为对于大量事件,开发部门不可能一次性完成所有埋点。以电商为例,购买流程的关键事件应当优先实施,与此冲突的都需往后排列;
- 考虑技术实现成本,比如有的埋点需要跨越多个接口,应该优先落实能够最快落地的,以确保技术准确性;
- 如果技术实现成本相同,就优先实施业务数据价值更高的。

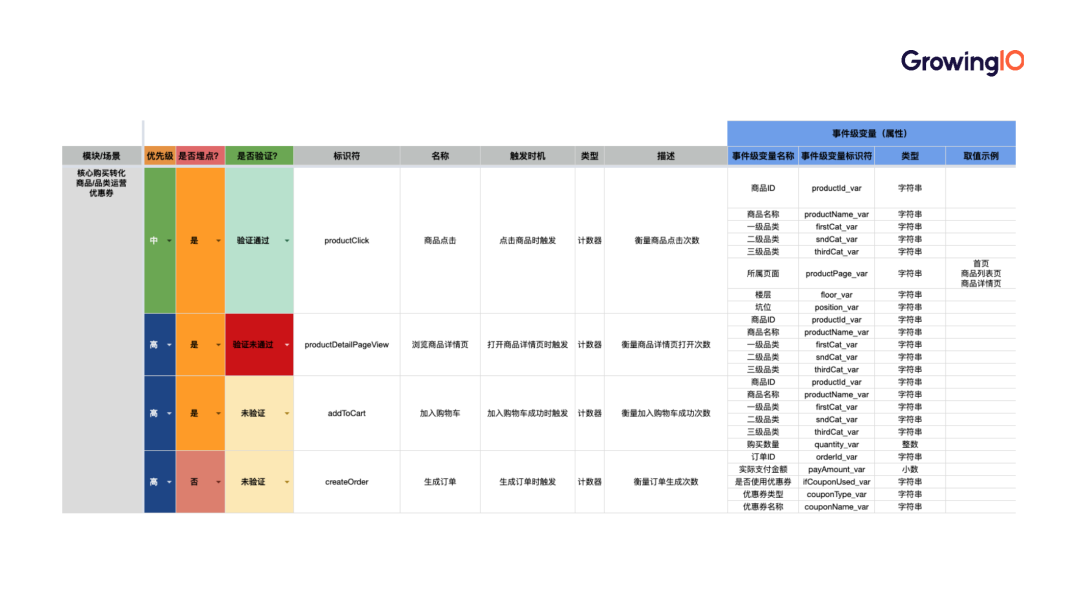
以下表格是我们整理出的模板,该表格完整承接埋点方案设计的四要素,可直接交给技术方进行埋点。
- 快:需求方希望方案快速落地,快速产生数据,以推动决策;这需要需求方、数据规划师、开发团队三方有序协作。
- 准:需要确保数据的数据质量和业务含义,保证数据采集的准确度和决策的正确性。

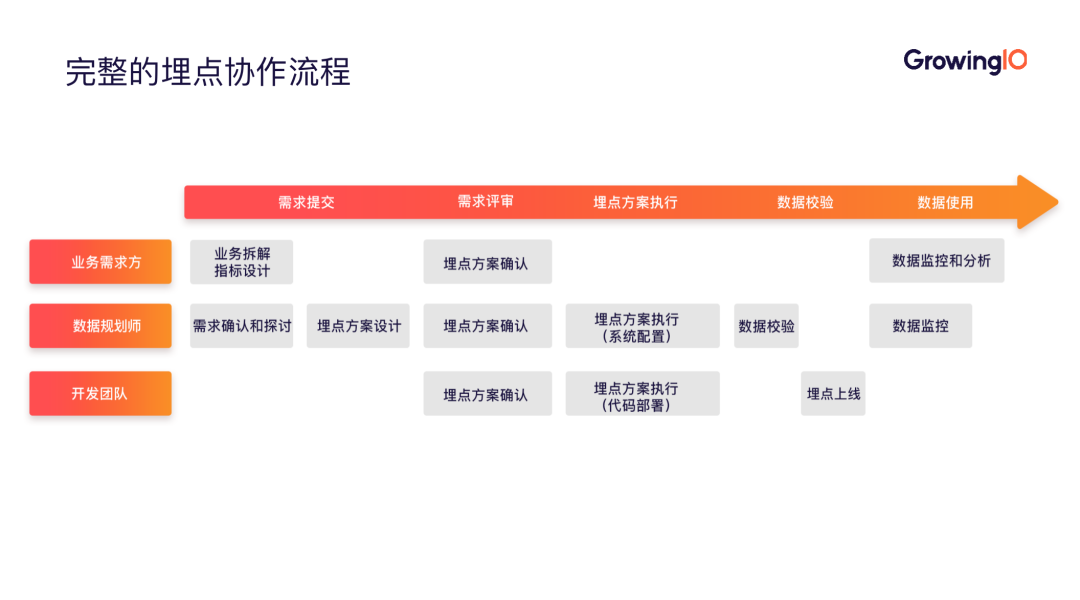
- 需求产生,需求方对业务指标进行拆解和设计,与数据规划师沟通,确认合理的采集点,形成埋点方案;
- 三方探讨技术实现成本,确认埋点方案;
- 开发团队和数据规划师执行方案,沟通埋点落实情况,呈现数据;
- 数据规划师进行数据校验,检查埋点时机和指标是否正确,过程是否完整;
- 程序发版上线,实现数据监控和分析。
2.具体场景演示
接下来将以某 App 的注册场景为例,帮助大家理解埋点方案落地的具体流程。
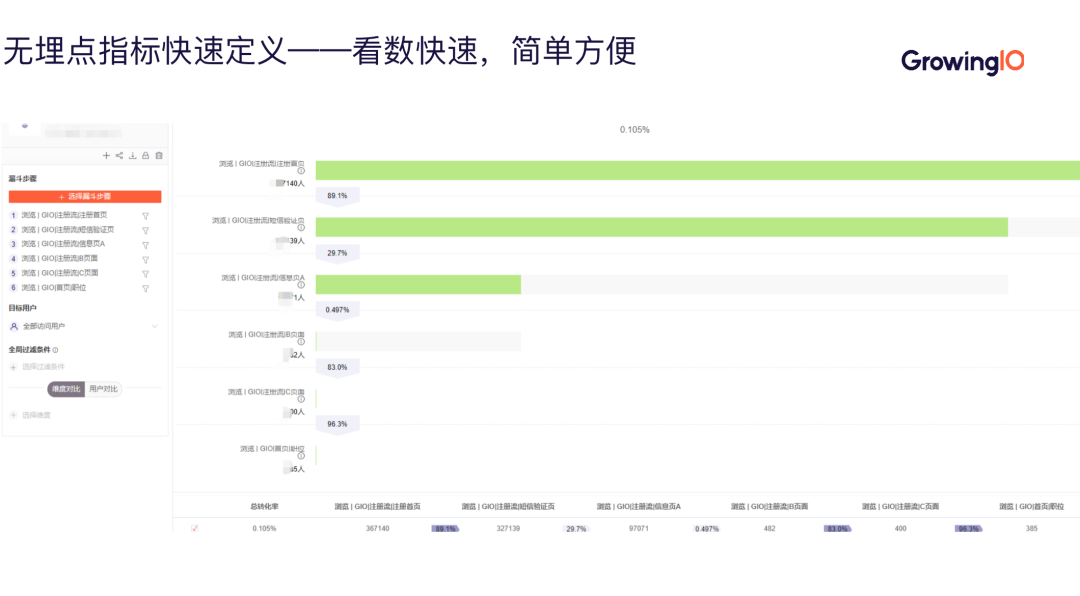
(注册首页填写手机号——注册验证输入短信验证码—注册信息 A、B、C——进入 App 首页)

可见,业务方单纯关心该流程间步骤的转化流程,那么我们就要关注用户的浏览行为动作,可以把指标定义为各个步骤间的页面。
具体来讲,登录动作从登录首页到进入登录后的首页共 6 步,而且我们的关注角度如机型、地区、国家等不属于业务范畴,都在预定义维度中,这就很符合我们无埋点指标的定义规则。
所以,我们可以快速定义出 6 个浏览页面指标,即可完成对于数据的分析。

客户的需求是:查看完成注册的用户中,填写实习行业和性别的分布情况。
根据完整埋点方案设计的四要素,我们应逐一确认:
- 事件:注册完成;
- 维度:实习行业、性别;
- 采用无埋点还是埋点指标:很明显,实习行业和性别是与业务相关的指标,我们需要通过埋点采集相关数据;
- 埋点的触发时机:在注册完成的回调中拿到性别及行业信息;
- 确认命名:事件——registerSuccess 注册完成;维度——practiceVocation 实习行业、sex 性别。

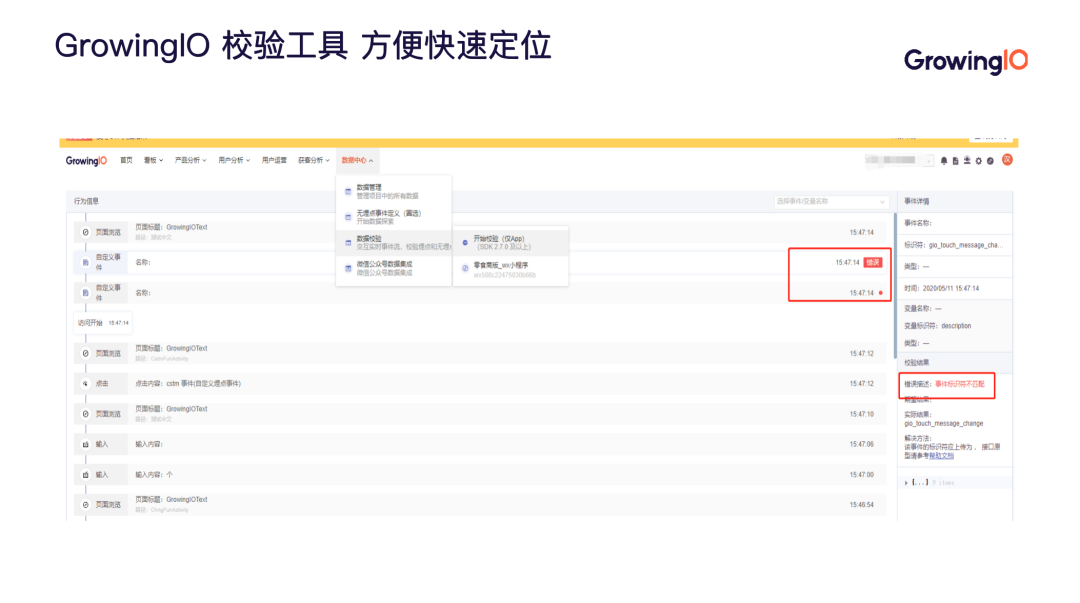
数据采集完毕后,还需要进行最终的确认,也就是我们通常所说的数据校验。
对此,GrowingIO 有一套完整的数据校验工具,可以快速定位数据产生的流程。如浏览了哪些页面、是否触发事件 、埋点事件是否与定义字段对应等。

 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


