谈到大数据,我们经常会提到数据拉通。数据拉通是一个非常基本但又很关键的一个环节,在用户画像、CDP(客户数据平台)和数据中台等应用场景下时,数据拉通是大家普遍绕不开的一道关卡。那么,问题来了,什么是数据拉通?如何实现数据拉通呢?今天就来回答有关数据拉通的问题。


一、什么是数据拉通
关于数据拉通,业内并未有统一定义。这里,笔者根据自己的理解,认为数据拉通可分为两种,即广义的数据拉通和狭义的数据拉通:
所谓广义的数据拉通是指按照一定的线索或口径,采取相应的方法,打破数据壁垒、消除数据隔阂,将原本分散的数据基于一定业务逻辑统一汇聚和拼接起来。简单一句话就是将分散的数据统一汇聚和拼接起来,这里数据对应的实体范围比较宽泛,既包括某种设备,也包括用户和某个物品等。
狭义的数据拉通则是指将原本分散的用户数据统一汇聚和拼接起来,形成完整的用户信息视图的过程。狭义的数据拉通所指的实体一般仅限于用户。本文重点讨论的就是狭义的数据拉通。
不论是广义还是狭义的数据拉通,数据的汇聚和拼接都是必不可少的动作。就如同老北京的冰糖葫芦一样,一根竹签能将几个不同的糖葫芦串在一起,而数据拉通要做的事情也是要将分散的数据用一根线贯穿和连接起来。这姑且称之为数据拉通的“冰糖葫芦论”吧。
二、为什么要做数据拉通
企业在与用户产生各种交互的过程中,会在不同渠道和触点留下相应的痕迹,然而这些数据往往都是按照不同的标识进行记录的。ID(Identifier)是指用于识别用户的标识符,在当前大数据的语境下,可以说一种ID实际上就对应了一个条线的数据,而我们则是被各种ID所标识,我们的数据就散落在各种ID对应的条线里。
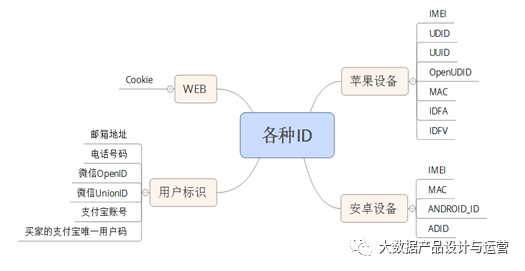
事实上,各种条线是站在不同的角度来组织工作的,他们分别代表着不同的组织机构和业务单元,有的是企业内部的,有些是属于企业外部的,他们之间往往存在着数据的隔阂。如果不将这些分散在不同条线的数据统一起来,企业在进行营销和服务时,就会遇到各种问题和麻烦。概括起来,需要做数据拉通的理由主要来自于三个方面:
1、数据资产沉淀的需要
对于企业而言,当进入数字化转型的战场后,数据资产的战略地位日益凸显,对数据资产的集中管理和全面整合就成为必须,实现数据互连互通是建立各类大数据平台的基础,类似CDP平台和数据中台就是数据资产沉淀的利器。数据拉通能消除数据壁垒,减少信息不对称,将分散的数据进行有序的串联和拼接,对于企业长期进行数据资产经营具有重要意义。
2、完善用户画像的需要
对于服务于C端用户的企业而言,渠道的碎片化无疑增加了数字化营销的难度。用户在不同的渠道和触点上随机穿梭,想要在营销策略上做到不重不漏实在太难,因此需要将用户在不同渠道上的标识拉通,以此来识别同一用户,从而消除数据孤岛,建立更完整的用户画像。这样既能对用户的数据资产进行统一化规整,也能全方位对用户旅程和行为模式进行深入洞察。
3、开展精细化运营的需要
数据拉通除了有利于企业的数据资产沉淀、建立更完善的用户画像外,还能在对用户的精准营销和个性化服务上发挥重要作用。在精准营销方面,通过数据拉通,能从横断面全方位了解用户在各个渠道和触点上的活动轨迹与行为特征,据此在营销策略制定时有助于营销资源的合理分配,可以避免对同一用户在不同渠道的重复营销,减少不必要的资源浪费,还能消除营销盲区,提高营销资源的利用率;在个性化服务方面,数据拉通后可以输出更完整的用户画像模型,企业可据此为某些用户制定个性化的服务策略,提供更精准有效的服务,对于维系用户、提升用户忠诚度也是大有裨益的。
三、数据拉通有哪几种方法
那么,到底有哪些方法可以实现数据拉通呢?常用的数据拉通方法,根据拉通的精准度可以分为两大类:精准拉通和模糊拉通。其中,精准拉通又分为强ID直接拉通和第三方助力拉通,模糊拉通又分为基于行为关联度的ID-Mapping、基于用户兴趣的聚类与合并。
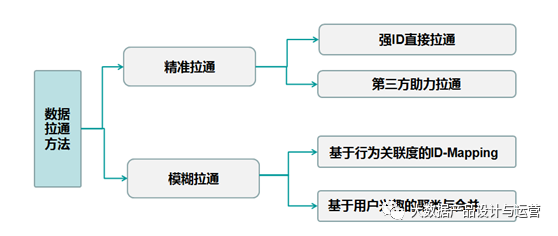
所谓精准拉通是指通过相应的技术手段实现数据拉通后能取得较高的准确率。而模糊拉通则是指通过一定的模型或算法识别两个关联ID的关联概率,在此基础上生成一个Super_ID实现了数据拉通,但用户拉通错误的概率较高。以下对数据拉通的方法逐一做个介绍。
1、 强ID直接拉通
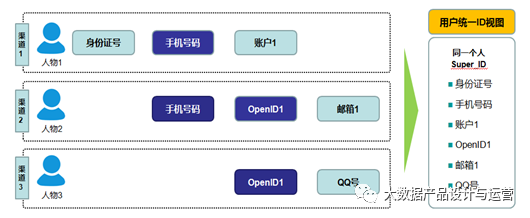
对用户出现在不同触点下的ID进行关联,可形成一个用户的统一ID视图,进而得到一个全局性的Super_ID,以标识一个唯一的用户,并由此建立Super_ID与其它ID的相互映射关系。如下图所示,用户的手机号和OpenID就是一种强ID,通过手机号和OpenID能将渠道1、渠道2和渠道3上的用户数据贯穿起来,形成全局性Super_ID下的统一ID视图。这种直接通过强ID实现数据拉通的方式对技术要求并不高,在了解清楚各数据源的字段结构后,一般只需要做数据源的清洗、去重和关联即可将其打通。
2、 第三方借力拉通
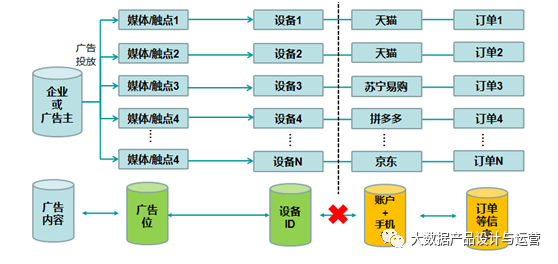
在某些情况下,光靠企业自身的数据是很难实现数据拉通的。例如,品牌主投放了大量的媒体广告,产生了曝光和点击数据,这些数据通过设备ID来标识用户。在广告投放的同时,品牌主在天猫、京东等电商平台上收到了大量的订单。品牌主可以从合作的媒体渠道那里得到广告内容与广告位、曝光和点击的数据,但是如果想进一步知晓哪些手机号码的用户在何种电商平台产生了订单,则还需要借助第三方电商平台的数据才可获得。品牌主一般不能同时具备设备ID和手机号的关联关系,这种情况下想要拉通数据只能借助第三方的数据能力。
目前市场上倒是有一些提供第三方数据并帮助品牌主进行数据拉通的服务商,建议品牌主在考核该类服务商时既要看拉通率、准确率等技术指标,还要注重其数据服务的合规性。
3、 基于行为关联度的ID-Mapping
在没有充足的Mapping预算、第一方数据源只能拉通一定比例的ID且存在大量数据无法打通的情况下,可以考虑采用ID-Mapping的方式作为补充解决方案。
基于行为关联度的ID-Mapping的基本原理是根据机器学习模型预测两个或多个ID之间的关联概率,关联概率较高的ID则可默认其对应一个用户、生成一个Super_ID,这样就能把关联概率较高的ID下的数据进行拼接打通。如下图所示,当ID1、 ID2 和ID3对应的行为相似度非常高,都跟篮球高度相关、都与准备购买斯伯丁篮球有关联,而且又是处于同一个IP地址之下,可以大概率认为三个ID对应的是同一个人,可生成为一个Super_ID,将三个ID对应的数据像糖葫芦一样串起来,从而实现数据的贯通。
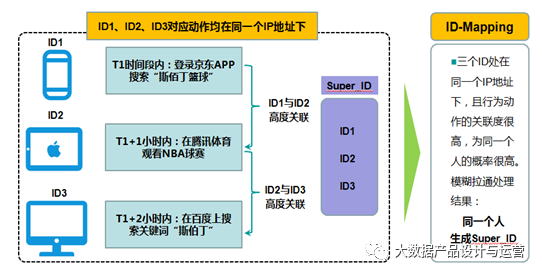
以上只是基于行为关联度做ID-Mapping的一个逻辑举例,为提高判断的准确度,可以继续为模型添加更多的判断维度,一般来说,纳入的判断维度越多、准确度就越高,但能够关联打通的数据比例就会下降。基于行为关联度的ID-Mapping适用于对可信度要求不高的推荐类场景,即使识别错误影响也比较小。但对于电商的短信通知服务等,如果识别错误,那么导致的用户体验则会非常差。
4、 基于用户兴趣的聚类与合并
“物以类聚,人以群分”,基于用户兴趣可以做相似用户的聚类和合并。例如:基于用户的上网时间偏好、网址访问偏好、点击行为特征、浏览行为偏好、APP使用偏好、社交账号偏好等,为每个用户提取上千个特征之后,进行相似用户的聚类。聚类中选择类中心附近的用户,再加上一些辅助准备进行判定,就可以把用户合并起来。
一般说来,基于用户兴趣的聚类与合并可以大幅度降低ID总量,但出现数据拉通错误的概率可能较高。
以上四种方式各有优缺点,综合比较如下:
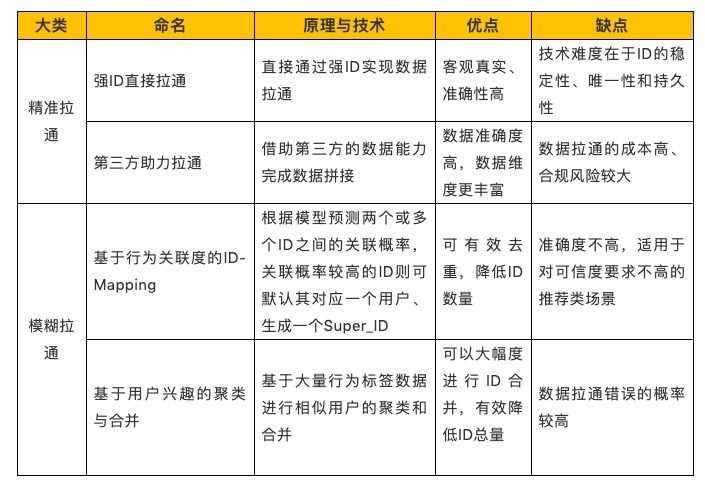 总之,精准拉通追求的是数据的准确性,而模糊拉通则更注重高合并和高去重,采用何种数据拉通方式,企业需要在追求合并和准确性之间进行平衡。
总之,精准拉通追求的是数据的准确性,而模糊拉通则更注重高合并和高去重,采用何种数据拉通方式,企业需要在追求合并和准确性之间进行平衡。
四、数据拉通有哪些注意事项
关于数据拉通需要注意的地方,简单提示两点:
1、 ID之间是多对多的关系
很多情况下,ID之间并不是一对一的关系。以最常用的手机号码与设备号IMEI之间的对应关系为例,手机号与IMEI是多对多的关系。比如:如果换了手机号但没有换手机,则不同的手机号会对应相同的IMEI号;如果换了手机,手机号码没有改变,则相同的手机号会对应不同的IMEI号;如果再考虑一些异常情况,比如“羊毛党”会用同一手机更换不同的手机号来获取品牌主或平台上的活动优惠,这也会产生同样的IMEI号对应多个手机号码的情况。有数据统计显示,国内手机号码与IMEI号之间为一对一的比例大约在76%,也就是说对于品牌主来说可能会有24%的曝光机会被重复浪费了。基于手机号与IMEI号之间是这种对应关系的情况,企业在做数字营销时,应当选取用户最常用的设备进行曝光,这样不仅可以保证实际触达率,还能减少不必要的重复曝光。
2、 ID持久化有一定的时效性
对于企业来说,都是希望能延长用户的生命周期,与用户建立持久的联系。然而,实际情况下,用户的ID确实是不稳定的。比如:Cookie ID 的有效期一般是1个月,IMEI有效期一般是1-2年。一些大数据公司也在试图做一些用户ID持久化的工作,比如在用户设备中植入某个持久ID,这样就可将改变后的ID关联到持久ID下,从而维护一个稳定的用户关系,但是随着安卓和苹果操作系统对数据获取的把控日趋严格,对非硬件厂商来说,ID持久化的难度也在加大。同时,ID都有一定时效性的事实也要求企业在做会员体系建设时要不定期的进行数据的更新和维护。
-END-
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


