编辑导语:B端产品往往有大量数据的需求录入,如果逐条将数据录入系统,将会花费不少的时间。同时,在大量重复同样的操作时,也会增加犯错的概率,导致录入的数据出现问题。为例解决这个问题,本文作者试想在批量数据录入场景下,通过数据导入功能,用户将正确的数据整理到表格中,快速导入到数据库,希望能给大家带来一些启发。


B端产品经常遇到大量数据录入的需求,如春季招聘完成后,给新招的120个员工建立员工档案,并创建员工帐号。如果逐条将大量的数据录入系统,将花费用户不少的时间。
新员工的员工信息通常会填写在一个excel表格中,人力在汇总后,录入系统。
如果逐个录入,每创建一个员工的员工档案,有以下几个步骤:
- 打开创建员工档案的表单页
- 对照着员工信息,在表单中输入员工姓名、手机号、身份证号······
- 保存数据
- 打开新的表单页,重复以上操作。
如果录入1个员工需要1分钟,那120个员工,就需要花费2个小时。
与此同时,用户在大量地、重复做同样的操作时,犯错的概率也会增加,导致录入的数据可能出现问题,如将张三的身份证号,错误地粘贴到了李四的员工档案中,或者填写到其他的字段中。
在批量数据录入场景下,数据导入功能,用户可以将正确的原始数据整理到表格中,快速导入到数据库,有效解决“逐条数据录入效率低下”和“操作失误导致数据错误”问题。
1. 如何设计批量数据导入功能
用户在批量导入数据前,需要先将要录入系统的数据,整理成导入文件。再将导入文件上传到系统中,系统完成数据校验后,再将导入文件中的数据,写入数据库。
从这个流程可以得出,批量数据导入功能的核心点有:合理设计导入模版、明确数据校验规则、异步导入数据、导入结果处理。
1.1 合理设计导入模版
由于excel具备强大的批量数据处理能力和便捷的操作体验,用excel整理导入文件是最合适的方式。
但用户自己并不清楚导入数据要如何整理导入文件中,因此我们需要设计一个导入模版,按业务数据表的格式要求,对要导入的数据进行格式规范,确保要导入的数据合法。
员工信息表中“性别”字段的要求是:必填、枚举类型(男、女),若导入表格中对应列的值出现了空值或“不详”,则数据非法。导入非法的数据,就会导致业务数据出现错误。
在设计导入模版时,要根据业务的实际情况,梳理出所有的字段,确定每个字段的格式要求,并给出对应的提示信息。具体要求如下:
- 明确字段格式:关键字段都要有明确的要求,以引导用户准确整理导入文件。如手机号字段必须是11位数字,性别必须是男、女中的一个值;
- 精确到最小颗粒:导入模版中的每一列,都要精确到最小颗粒,尽量不要将多个字段混在一列中,否则在校验数据时,必须要先拆分单元格的内容,才能对单个数据值进行校验,增加数据校验的复杂度。如省、市、区应该分3列,而不是一列导入;
- 在表格中给出填写规范提示信息,以减少用户填写错误的概率。
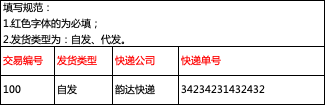
在导入数据前,要引导用户下载导入模版,并按模版中的格式要求,整理好需要录入系统的数据。
1.2 明确数据校验规则
1.2.1 导入文件格式校验
数据校验的第一步,是校验导入文件的格式是否正确。如果导入文件格式只支持excel,而用户上传了pdf格式的文件,那导入一定无法完成。
1.2.2 导入文件表头校验
格式校验没问题后,再校验导入文件表头是否与数据表中,需要导入的字段是否匹配。
表头校验的方法是:将导入文件的表头每个字段与数据表需要导入的字段逐一比对,检查同一序号对应列的字段名是否一致。
只有导入文件所有字段序号和字段名与数据表完全一致时,导入文件表头校验才匹配。
- 导入文件中第一列是“手机号”,但数据表第一列是“姓名”,即为不匹配;
- 导入文件中第一列是“手机号”,数据表第一列是“手机号码”,也是不匹配。
数据导入时,系统会按照字段名进行匹配,将导入文件中的数据,写入数据表中对应位置的、同名的字段中。
若不匹配,在数据导入时,导入文件中的数据无法找到对应的数据表字段,从而无法导入。
1.2.3 导入文件字段值校验
表头校验正常后,再对导入文件中具体的字段值做校验,确认其是否合法。
如果不对字段值进行合法性校验,直接导入到数据表中,就有可能导致业务数据错误,甚至引发严重事故。
导入文件中“奖励积分”列的值,本来应该填写奖励的积分数量,但被错误地填入了用户手机号,结果导致每个用户发放了100多亿个积分。
字段值校验的方法是:根据数据表对各个字段值的格式定义,逐个检查导入文件中的对应字段的值是否合法。
字段值校验可能会遇到以下不合法的情况:
- 基本要求不满足:导入模版中有要求值的字符类型、字符长度、业务规则限制,但导入文件就中的值不满足。若强行导入,会导致数据错误。如导入模版要求是11位数字,导入文件的值是中英文的字符;
- 找不到匹配的值:导入文件中的部分字段的值,要求在已有数据表中存在,但数据表中查不到。若强行导入,会导致该数据找不到对应的归属主体。如导入文件中“用户ID”的值,在用户表中找不到;
- 与其他字段的值不匹配:某几个字段的值之间有联动关系,但导入文件中的值联动关系错误。若强行导入,会导致对应数据错乱。如导入文件有员工籍贯所在地,分省、市、区3列,若省的值为广东,则该条数据中,市的值必须是广东省的地级市,不允许出现了其他省的市。
数据校验完成后,根据数据校验结果,决定是否导入数据,或导入哪些行的数据。对于所有列的值都合法的数据行,可以直接导入;而数据行的任意一列的值不合法,则该行数据无法导入。
1.3 使用异步方式,快速导入正确数据
在批量录入数据的场景下,用户的核心需求是:快速将数据录入系统。产品方案应该要围绕该核心需求来设计。
1.3.1 字段值完全正确的数据行,可以直接导入
在执行数据导入前,我们有必要先确定导入文件中,每一行的数据都完全正确吗?
其实并不需要。
用户在整理导入文件时,难免会出一些小错误。比如导入文件有100行数据,某1行数据的某个值错误,但剩下的99行数据的值都是正确的。
如果要求所有数据都完全正确,才能被导入,那就会导致完全正确的大部分数据,不能更“及时”地录入系统中,必须要将其中极少数错误的数据修正后,重新检验数据,再尝试导入。
更高效的做法是:导入文件中,字段值完全正确的数据行,可以直接导入,而错误的部分数据行,提供下载功能,让用户修改后,重新导入。
1.3.2 覆盖更新已有数据
在系统导入过程中,若某条数据在系统中已经存在,而导入文件也包含了该条数据,此时应该如何处理?
在产品的角度看,通常有三种处理方式:
- 不允许导入。若用户需要更新该条数据,就需要先删除已有数据再重新导入,或到系统中修改;
- 询问用户是否要覆盖已有数据。系统要找出已存在的数据,标记两者之间的差异,用户选择是否要更新后,自动执行;
- 直接覆盖已有数据。用户无需做任何处理。
很明显,第3种处理方式的用户操作成本及研发成本都是更低的。
导入5月份的考试成绩时,通过学号查询,发现张三的成绩已经导入过了。此时将根据导入数据,更新张三的成绩。
采用这种方式,默认了需要导入的数据,比系统中已存在的数据更及时、更准确。因此我们必须要用户:若检测到导入数据在数据表中已存在,则更新该条数据。
1.3.3 系统异步处理
如果需要导入的数据量大,且系统性能不足,系统就要花费较长的时间来处理。
在等待系统处理完成期间,用户想关掉导入页面,去做其他操作,怎么办?
从研发的角度看,系统处理数据,通常有同步和异步两种方式。
- 同步:指发起请求后,后端必须立即响应,处理完成时返回结果。
- 异步:指发起请求后,后端会先接收请求,并在“自己”方便的时候进行处理,处理完成后,再返回结果。
如果使用同步方式,就会导致用户等待时间过长,甚至最后可能因为超时而导入失败,给用户带来极大的负面感受。
而使用异步方式导入,用户上传文件后,即可关闭导入窗口,放心地去做其他操作,且不会应超时而导入失败。
异步导入,既避免用户浪费时间等待,又降低了导入失败的概率,用户体验明显更好。
1.4 显示导入结果,引导下载导入失败数据
数据导入完成后,需显示导入结果,告知用户导入成功了多少、失败了多少。
对于导入失败的数据,提供下载导入失败数据的入口,并在导出文件中标记出不正确的值。这样,用户可以在修正后,重新导入。
2. 批量导入方案的优点
上文描述的批量导入方案,不仅能满足用户批量录入数据的需求,还能低成本地复用到其他功能模块。
使用异步的方式来导入,用户将导入文件上传到系统后,即可放心地去做别的工作,数据导入完成后,再来查看导入结果。大幅度提升了数据录入效率。
当另一个功能模块也需要用到数据导入功能时,只需要修改导入模版和字段值校验规则,即完成产品方案设计和开发。有效提升了产品方案输出和功能开发的效率,降低人力成本。
3. 总结
批量数据导入能快速将数据录入系统,降低企业的人力成本。
在设计产品方案时,应该在确保导入性能足够的条件下,避免用户等待,并降低产品和研发的人力成本,提高用户和产品研发团队的工作效率。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


